您现在的位置是:主页 > 慢生活 >
苹果港大学联合团队建议使用扩散语言的扩散器
发布时间:2025-07-01 10:24编辑:bat365在线平台官网浏览(82)
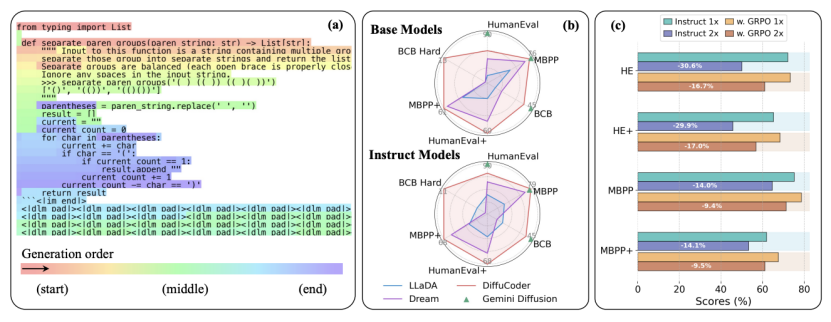 资料来源:DeepTech最近,扩散语言模型(DLM,扩散模型)吸引了越来越多的关注。 Inception Labs发布了第一级商业级DLM水星后,Google之前也发布了DLM Gemini爆炸。由于一代人的独特机制,扩散模型显示了代码生成活动的巨大潜力,尤其是在提高世代速度和代码结构的发展方面,这被认为是独特的。但是,对于研究人员和开发人员而言,许多人仍然不知道语言活动中扩散模型的内部工作机制(尤其是代码的生成)。他们如何在世界各地计划?一代过程和自回归模型之间的重要区别是什么?如何优化南方?最近,一篇论文“ diffucoder:理解和改进了代码生成的蒙版扩散模型”香港大学的苹果公司和研究人员的棚屋已经系统地回答了关键问题。这项研究不仅启动了70亿参数的扩散代码的开源代码,而且还审查了扩散模型的解码,并提出了研究为其定制的强化的概述。照片| (a)当采样温度为1.2时,解码扩散器结构的真实过程的示例; (b)基准结果的审查; 。这种机制在确保以下方面的逆境方面非常好,但是重要的非线任务(例如代码生成)存在一些局限性。编程过程的过程涉及在不同的代码块,预先计划结构和随后的补充依赖性之间跳跃,这很难直接模拟自动回归生成的单向模式。相比之下,扩散模型采用了迭代的“否定”过程。我t从接下来的续集开始 - 涵盖的[掩码],同时检查所有位置 - 与许多迭代相同的时间,然后逐渐用单词的实际元素替换[mask]。这一一代的全局和并行方法更适合处理具有复杂结构依赖性的代码等任务。为了发展扩散模型的实际行为,研究团队引入了一个名为“自动加入性”(AR-NES)的量表。该指标来自“ LocalContining”(模型模型模式的模型模式是根据两个方面进行审查的:产生单词相邻单词的趋势)和“全局exequation”(从左到右填充的趋势)。综述的结果表明,解码时的扩散模型不是完全随机的。更高的人可以立即预测直接单词右侧的位置,研究人员称此“熵锌”。该模型可以调整生成流动的方法借给借口的作品。研究还发现,采样温度对扩散模型有两个影响。在自回旋模型中,温度升高主要用于增加单词选择的差异。但是在扩散模型中,温度变化显着影响其对“发展的地方”的决策。提高的采样温度将使一代人的一代模型更加灵活,多样,并且不仅限于从左到右。增加差异 - 不同的行为是指随后收集增强的方向。图丨不同采样温度(来源:ARXIV)的影响是当前的主要方法,而奖励信号通常来自单位代码上的PATEST的通过率。但是,应用标准算法来加强传播模型面临挑战,主要是需要高C准确的成本准确估计发展逆境的可能性,以及压力的过程将引入高差异 - 不同的是,导致幽默感。为了解决这个问题,研究小组提出了一种加强研究算法,称为“耦合GRPO”。该算法的核心是引入辅助配对采样掩码方案。在训练的每个步骤中,该算法为同一代码样本创建了一对辅助掩码。例如,如果一个口罩在对手中占据特殊的位置,则另一个面具将完全占据上诉。使用此设计,可以在同一传播模型中评估每个单词一次。照片|分配器训练阶段过程和会员GRPO算法的示意图(来源:ARXIV)机制“耦合采样”具有许多优势。首先,它保证对所有词汇元素进行完整分析。其次,评估单词的每个元素在轻微的情况下,比被评估到完全孤立的(完整掩码)的情况下更接近解码的真实状态,从而大大降低了差异 - 可能性估计。该方法基于反基本差异的统计原则,理论上的差异可以确保并使教育过程更加稳定。研究团队是Diffucoder的性能已证明了许多代码生成基准。结果表明,已经对1300亿个单词yuan进行了预先培训的基本差异模型的性能与QWEN2.5编码,OpenCoder等进行了比较。资源回归模型的开放资源是可比的。与教学教学的精致版本相比,受过训练的GRPO模型还取得了4.4%的评估绩效(此改进仅使用21,000个培训样本)。照片|基准测试结果(来源:ARXIV)进一步分析表明,pimimimimin奥德尔(Odel)降低了“自动加入性”,并且更容易平行地适应。当对解码的步骤数被划分(即双重速度)时,将模型性能拒绝的eventhat较小。它表明,该模型对世代的严格形成的希望已减少,这可以更好地释放平行生成的扩散模型的潜力。参考材料:1。https://arxiv.org/pdf/2506.20639类型:刘Yakun
资料来源:DeepTech最近,扩散语言模型(DLM,扩散模型)吸引了越来越多的关注。 Inception Labs发布了第一级商业级DLM水星后,Google之前也发布了DLM Gemini爆炸。由于一代人的独特机制,扩散模型显示了代码生成活动的巨大潜力,尤其是在提高世代速度和代码结构的发展方面,这被认为是独特的。但是,对于研究人员和开发人员而言,许多人仍然不知道语言活动中扩散模型的内部工作机制(尤其是代码的生成)。他们如何在世界各地计划?一代过程和自回归模型之间的重要区别是什么?如何优化南方?最近,一篇论文“ diffucoder:理解和改进了代码生成的蒙版扩散模型”香港大学的苹果公司和研究人员的棚屋已经系统地回答了关键问题。这项研究不仅启动了70亿参数的扩散代码的开源代码,而且还审查了扩散模型的解码,并提出了研究为其定制的强化的概述。照片| (a)当采样温度为1.2时,解码扩散器结构的真实过程的示例; (b)基准结果的审查; 。这种机制在确保以下方面的逆境方面非常好,但是重要的非线任务(例如代码生成)存在一些局限性。编程过程的过程涉及在不同的代码块,预先计划结构和随后的补充依赖性之间跳跃,这很难直接模拟自动回归生成的单向模式。相比之下,扩散模型采用了迭代的“否定”过程。我t从接下来的续集开始 - 涵盖的[掩码],同时检查所有位置 - 与许多迭代相同的时间,然后逐渐用单词的实际元素替换[mask]。这一一代的全局和并行方法更适合处理具有复杂结构依赖性的代码等任务。为了发展扩散模型的实际行为,研究团队引入了一个名为“自动加入性”(AR-NES)的量表。该指标来自“ LocalContining”(模型模型模式的模型模式是根据两个方面进行审查的:产生单词相邻单词的趋势)和“全局exequation”(从左到右填充的趋势)。综述的结果表明,解码时的扩散模型不是完全随机的。更高的人可以立即预测直接单词右侧的位置,研究人员称此“熵锌”。该模型可以调整生成流动的方法借给借口的作品。研究还发现,采样温度对扩散模型有两个影响。在自回旋模型中,温度升高主要用于增加单词选择的差异。但是在扩散模型中,温度变化显着影响其对“发展的地方”的决策。提高的采样温度将使一代人的一代模型更加灵活,多样,并且不仅限于从左到右。增加差异 - 不同的行为是指随后收集增强的方向。图丨不同采样温度(来源:ARXIV)的影响是当前的主要方法,而奖励信号通常来自单位代码上的PATEST的通过率。但是,应用标准算法来加强传播模型面临挑战,主要是需要高C准确的成本准确估计发展逆境的可能性,以及压力的过程将引入高差异 - 不同的是,导致幽默感。为了解决这个问题,研究小组提出了一种加强研究算法,称为“耦合GRPO”。该算法的核心是引入辅助配对采样掩码方案。在训练的每个步骤中,该算法为同一代码样本创建了一对辅助掩码。例如,如果一个口罩在对手中占据特殊的位置,则另一个面具将完全占据上诉。使用此设计,可以在同一传播模型中评估每个单词一次。照片|分配器训练阶段过程和会员GRPO算法的示意图(来源:ARXIV)机制“耦合采样”具有许多优势。首先,它保证对所有词汇元素进行完整分析。其次,评估单词的每个元素在轻微的情况下,比被评估到完全孤立的(完整掩码)的情况下更接近解码的真实状态,从而大大降低了差异 - 可能性估计。该方法基于反基本差异的统计原则,理论上的差异可以确保并使教育过程更加稳定。研究团队是Diffucoder的性能已证明了许多代码生成基准。结果表明,已经对1300亿个单词yuan进行了预先培训的基本差异模型的性能与QWEN2.5编码,OpenCoder等进行了比较。资源回归模型的开放资源是可比的。与教学教学的精致版本相比,受过训练的GRPO模型还取得了4.4%的评估绩效(此改进仅使用21,000个培训样本)。照片|基准测试结果(来源:ARXIV)进一步分析表明,pimimimimin奥德尔(Odel)降低了“自动加入性”,并且更容易平行地适应。当对解码的步骤数被划分(即双重速度)时,将模型性能拒绝的eventhat较小。它表明,该模型对世代的严格形成的希望已减少,这可以更好地释放平行生成的扩散模型的潜力。参考材料:1。https://arxiv.org/pdf/2506.20639类型:刘Yakun
上一篇:小米汽车很“热”,泰恩·旺利(Taihong Wanli)无
下一篇:没有了